Navigating the labyrinth when it comes to data storage and management solutions is not for the faint of heart. As institutions of higher education expand their data capabilities to gain insights and make informed decisions, understanding the distinct types of data storage and analytics platforms becomes essential. Today we explore four of these platforms—operational databases, data warehouses, data lakes, and data lakehouses to decipher their differences, strengths, and weaknesses to lay out a comprehensive view that could guide strategic choices in data analytics, reporting, and business intelligence. Understanding the complex ecosystem of data storage and analytics can be daunting, particularly as technology continually advances is essential for strategic decision-making.
Operational Databases
An operational database (or transactional database), also known as an OLTP (Online Transaction Processing) system, is engineered to manage fast, transactional data processes. These are the databases that your applications often interact with during day-to-day operations such as course registrations, entering grades, etc.
Detailed Characteristics:
- Structured Data: Built to handle structured data, which includes well-defined data types like integers and strings.
- ACID Compliance: Ensures Atomicity, Consistency, Isolation, and Durability to maintain database integrity during transactions.
- Real-Time Access: Enables quick, on-the-fly data retrieval and modification, making it ideal for real-time analytics and immediate updates.
Use-Cases with Examples:
- Customer Relationship Management (CRM): Tracks prospect/applicant interactions and stores this information for future reference.
- Course Registration Systems: Maintains real-time information about course registrations, seats remaining, when courses are offered and staffed, etc.
-
IE, Banner
Limitations and Challenges:
- Limited Analytical Capabilities: Not designed for heavy analytical workloads or complex queries that involve multiple tables.
- Scalability: Although capable of fast transactions, it may not efficiently handle large volumes of historical data.
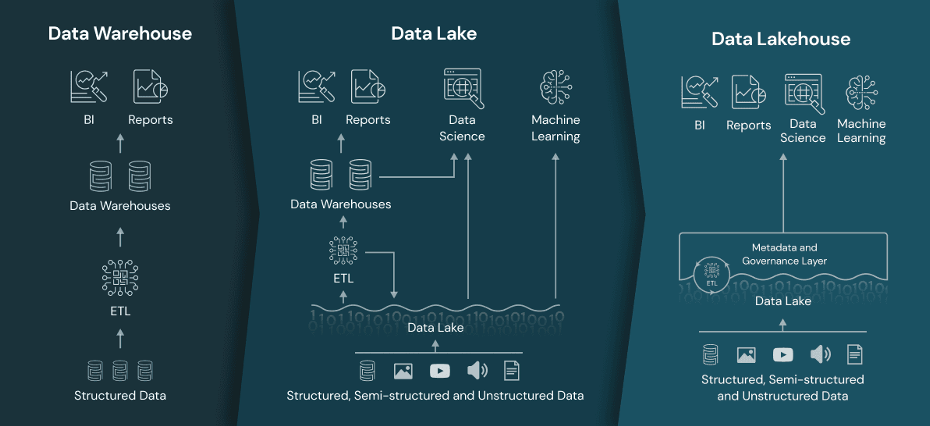
Data Warehouses
A data warehouse is a structured repository designed to store large volumes of data and make it accessible for querying and analysis. Data warehouses are designed for high-speed, complex query execution, making them excellent for deep analytics and reporting. They serve as a centralized repository where data from various sources is stored after ETL (extraction, transformation, loading) processes, offering a ‘single source of truth’. Data warehouses are ideal for storing historical data, which can be invaluable for trend analysis and long-term strategic planning.
Detailed Characteristics:
- Semi-Structured Data: Supports structured and semi-structured data but requires transformation into a specific schema for easier retrieval.
- Batch Processing: Data is usually updated during off-peak hours through ETL (Extract, Transform, Load) processes.
- Query Optimization: Features such as columnar storage and data indexing are prevalent for speedy query execution.
Use-Cases with Examples:
- Business Intelligence: Powers Business Intelligence (BI) tools to provide in-depth analytics, trend analysis, and data visualization, ie, transformed Banner data for query/data optimization.
- Market Research: Aggregates and analyzes data from various sources for a comprehensive market outlook.
Limitations and Challenges:
- Cost: High upfront and maintenance costs, particularly for on-premises solutions.
- Data Latency: Due to batch processing, the data may not always be up-to-date.
Data Lakes
A data lake is a large storage repository capable of holding raw, unstructured data in its native format, typically scalable to petabytes of storage.
Detailed Characteristics:
- Unstructured Data: Ideal for housing raw, unstructured data such as logs, sensor data, and multimedia files.
- Schema-on-Read: Unlike databases that apply a schema when data is written, a data lake applies the schema only when the data is read, meaning an analyst identifies the data sets before they are compiled.
- High Scalability: Can be expanded to store massive amounts of data.
Use-Cases with Examples:
- Big Data Analytics: Supports big data platforms like Hadoop for advanced analytics.
- IoT Applications: Stores data from IoT devices for future analysis.
- Machine Learning: Provides a fertile ground for machine learning models that require a large, diverse dataset.
Limitations and Challenges:
- Data Governance: The lack of structure can make data governance challenging, risking data swamp scenarios.
- Security Concerns: Storing sensitive or regulated data may require additional layers of security and compliance mechanisms.
Data Lakehouses
A data lakehouse aims to bring together the best aspects of both data lakes and data warehouses, providing structured and unstructured data storage. Combining features of both lakes and warehouses, lakehouses offer a single platform for batch and real-time analytics, thus eliminating data silos. Lakehouses are well-suited for dealing with structured and unstructured data and by leveraging cheaper storage solutions, lakehouses can be a more economical way to store large volumes of raw data.
Detailed Characteristics:
- Unified Data: Designed to support structured, semi-structured, and unstructured data.
- Real-Time & Batch: Enables both real-time and batch data processing, making it highly versatile.
- Advanced Analytics Support: Built-in features for handling advanced analytical queries and machine learning algorithms.
Use-Cases with Examples:
- Real-time Analytics: Simultaneously provides real-time dashboards and historical trend analysis.
- Machine Learning and AI: Stores data for machine learning models and runs algorithms for predictive analytics.
- Unified Data Platform: Acts as a single repository for all organizational data, streamlining governance and accessibility.
Limitations and Challenges:
- Maturity: Being a relatively new concept, lakehouses are still evolving, and best practices are not yet fully established.
- Complex Data Governance: Managing data across such a flexible architecture can be challenging and may require sophisticated governance strategies.
Side-by-Side Comparison
- Complex Query Capability:
- Data Warehouse: High
- Data Lakes/Lakehouse: Moderate to High
- Operational/Transactional Database: Low
- Real-Time Analytics:
- Data Warehouse: Low
- Data Lakes/Lakehouse: High
- Operational/Transactional Database: High
- Cost Effectiveness:
- Data Warehouse: Low
- Data Lakes/Lakehouse: High
- Operational/Transactional Database: Moderate
- Data Type Compatibility:
- Data Warehouse: Structured
- Data Lakes/Lakehouse: Both
- Operational/Transactional Database: Structured
- Scalability and Performance:
- Data Warehouse: Scalable but can be costly
- Data Lakes/Lakehouse: Highly Scalable
- Operational/Transactional Database: Scalable but optimized for specific transactional tasks
No one-size-fits-all approach exists when choosing a data storage and reporting/analytics platform. The decision should be aligned with organizational goals, the nature of the data, and the specific insights desired because choosing amongst a data lake, data lakehouse, data warehouse, and using operational/transactional databases is critical. In today’s data-driven, data-informed landscape where near, real-time data is a necessity, having a single storage or processing system for all data needs will be restrictive. Utilizing a combination of these technologies can offer a more comprehensive data strategy, enabling an organization to meet diverse needs efficiently. Each has its place, and the best solution may even be a hybrid approach that leverages the strengths of multiple platforms. Having any combination in one’s toolbox is like having a Swiss Army knife for your data needs since each offers unique advantages that, when combined, provide a versatile and robust data infrastructure. This multi-pronged approach ensures that whatever the data demands are—be it real-time analytics, deep historical insights, or machine learning capabilities—you are well-equipped to handle them.
The next time you find yourself debating which data storage and analytics technologies you should choose to implement at your organization, you now have the essential differences to refer to.
To choosing your best database storage options, illuminated with data!
Brian M. Morgan
Chief Data Officer, Marshall University